

DMTN-330
Publication flow for Butler prompt data products#
Abstract
Describes the system supporting the end-user prompt data products Butler repository and the process of making data available in it.
System Overview#
The following diagram shows an overview of the dataflow for Prompt Processing outputs. Items shown with a dotted border are not currently deployed.
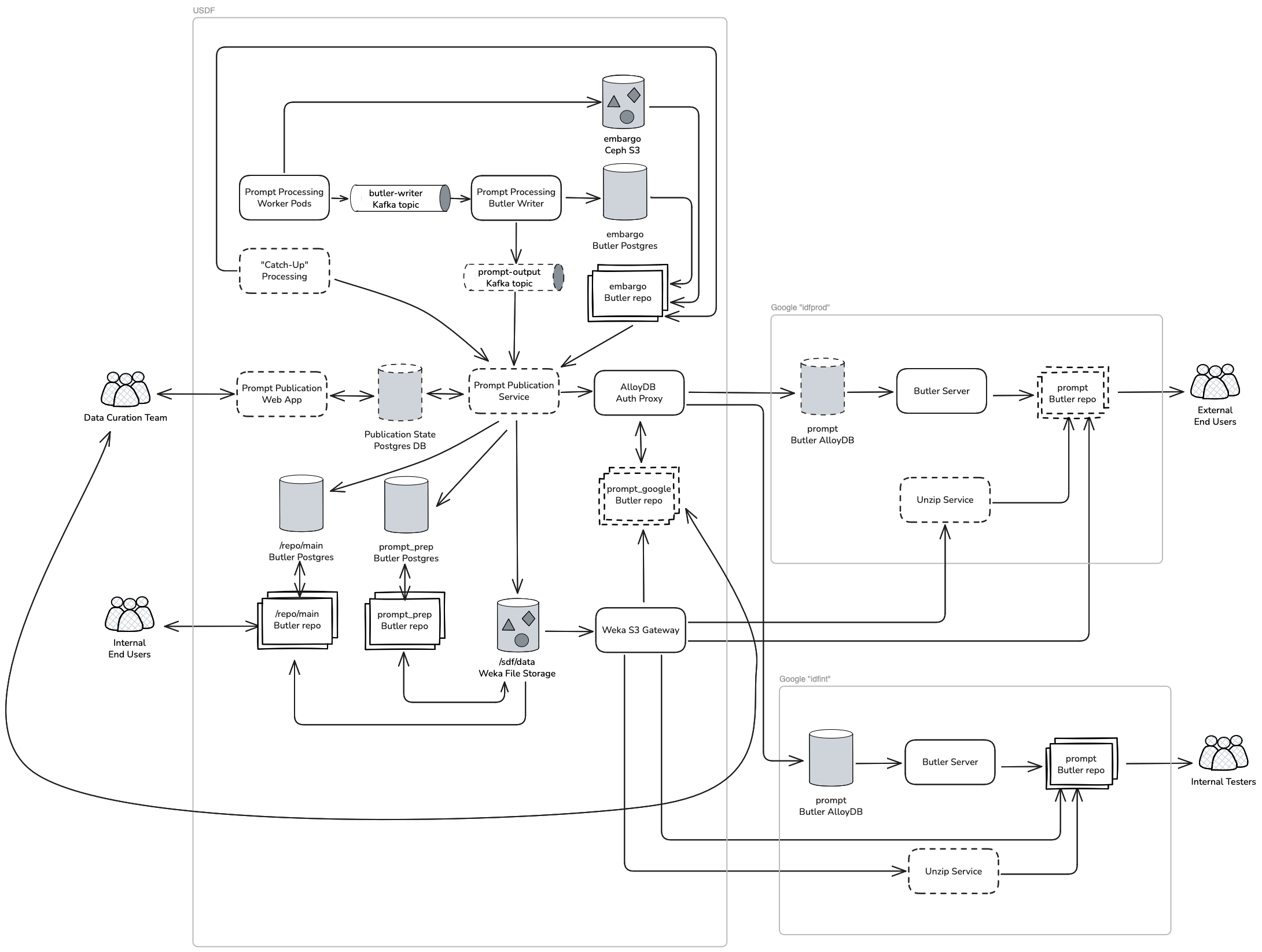
Fig. 1 System diagram#
Prompt Processing outputs originate inside Prompt Processing worker pods. The workers transfer the outputs to a central Ceph S3 file store in the embargo rack. The workers then send a Kafka message to notify the Prompt Processing Butler Writer service that the datasets are available for ingestion. The Prompt Processing Butler Writer batches up the messages from the workers, then inserts records for the datasets into the Butler database.
This tech note proposes modifying the Prompt Processing Butler Writer to log ingested datasets to another Kafka topic. A new service, the Prompt Publication Service, would use that Kafka topic as the source of truth to generate the list of datasets available for unembargo and publication.
The Prompt Publication Service will be responsible for transferring datasets
from the embargo repository to two USDF Butler repositories: /repo/main and
prompt_prep. It will publish the datasets to repositories in Google Cloud
for delivery to end users, and expire them when they are no longer needed.
Butler server at Google Cloud will serve a Butler repository to end users. The Butler database for this repository will be hosted in AlloyDB in the cloud. The artifact files will be hosted at USDF in Weka, and served to end users via the Weka S3 gateway.
Files that will be published#
An initial list of Butler dataset types that will be published is currently being tracked in Confluence and is being finalized in RFC-1134.
Most of the items on that list are outputs of Prompt Processing, and this tech note is primarily concerned with those. There are two major types of dataset that are not Prompt Processing outputs:
Raws
Calibrations and ancillaries
Raws will eventually be integrated into the Prompt Publication Service, but they have a slightly different lifecycle (originating outside of Prompt Processing, getting combined into zip files upon unembargo and being retained forever.) They are not discussed in detail here.
Calibrations and ancillaries are currently updated on an ad-hoc basis by the calibration team. The calibration team has scripts that are used to synchronize the calibration collections between different Butler repositories. In the short term, these scripts could be extended to also synchronize to the end-user repositories at Google. We may eventually need a more regimented system for publication of these datasets, but it is outside the scope of this tech note.
Existing unembargo tooling#
The transfer_embargo repository
contains scripts that are currently used to move raws and other outputs from
the embargo repository to other repositories at USDF. However, these scripts
do not track any state about which files have been transferred (other than
implicitly in each Butler database.) That will make it difficult to reliably
implement the full lifecycle of these data products across multiple
repositories. It will also be easier to reason about concurrency with a single
instance of a service, rather than individual scripts being started as cron
jobs that may overlap.
Lifecycle of Prompt Processing Outputs#
The following is the rough sequence of tasks for publication of Prompt Processing outputs to end users.
Prompt processing pods:
Generate outputs in a local Butler repository
Copy files to central
embargoButler repository S3Write dataset metadata to Kafka for consumption by writer service
Prompt Processing Butler Writer
Read dataset metadata from Kafka and write it to central
embargoButler repository PostgresWrite list of output datasets to Kafka for consumption by publication service
Prompt Publication Service:
Read list of datasets to unembargo from Kafka
After 80 hours, copy files and metadata from
embargotoprompt_prepButler repositoryCopy metadata and make hardlinks from
prompt_prepto/repo/mainButler repositoryDelete datasets from
embargoButler repositoryCopy metadata from
prompt_prepto end-userpromptrepository at GoogleAfter dataset lifetime elapsed, mark datasets as expired in end-user
promptrepository at GoogleDelete files from
prompt_prepButler repositoryDelete files from
/repo/mainButler repository
The Prompt Publication Service may end up doing additional work that is not listed here – for example notifying other systems that data has been unembargoed and is available for further processing/publication.
Batched vs incremental release of datasets#
It has been suggested that prompt data products should be released in a batch once a day, rather than being incrementally delivered as they come out of the embargo period. Doing a once-a-day release would have some downsides for datasets delivered by the Butler:
It concentrates downloads of new files at a single point in time, rather than spreading it out over many hours.
It may require us to modify the Butler database schema to introduce a concept of “published” vs “unpublished” datasets, so that we can incrementally load the database but release publicly at the scheduled time. (We initially plan on releasing approximately 3 million datasets per day. That is larger than DP1, which took 30-60 minutes to load into the databases at Google in a single database transaction.)
It complicates the implementation of the publication service by requiring it to handle a large number of datasets in a single group, instead of small chunks.
An incremental release will increase the number of times users hit the Butler server or other search services to query for new datasets. We could mitigate this issue by providing a way for users to be notified of newly-released datasets. For example, we could provide webhooks, or lists of datasets in static files that they can poll via HTTP.
While either batch or incremental release of datasets could be made to work, incremental release will take less work to implement and is likely to be more reliable because it spreads out the work over time.
Prompt Publication Service#
Most of the work in the publication process will be handled by a new service: the Prompt Publication Service (“PPS”). This service will run in Kubernetes at USDF.
State Database#
PPS will maintain a database tracking the state of each dataset as it moves through its lifetime. Conceptually, the state will look something like the following:
Dataset ID |
Dataset Type |
Exposure Time |
embargo status |
prompt_prep status |
repo_main status |
Google status |
Google publication time |
|---|---|---|---|---|---|---|---|
b8e9d6b8-d961-4eea-bfa0-2dae310df6cf |
preliminary_visit_image |
2026-03-15 1am |
PRESENT |
||||
bdc5e4c9-077e-4eb4-86ff-5cf1b2f0a328 |
preliminary_visit_image |
2026-03-11 11pm |
DELETED |
PRESENT |
PRESENT |
PRESENT |
2026-03-14 11pm |
b587b20d-0d1a-4b15-9502-24cc61856642 |
difference_image |
2026-02-05 12pm |
DELETED |
DELETED |
DELETED |
EXPIRED |
2026-02-08 1am |
This is sufficient information to allow the service to efficiently find datasets that are ready to move to the next state.
The insertion of new datasets into this database is triggered by a Kafka
message received from the Prompt Processing Butler Writer on the
prompt-output topic. Kafka’s transactions can be used to guarantee
at-least-once processing of these messages.
Besides Kafka notifications, we can also accept lists of datasets from other sources. For example, Prompt Processing “catch up” processing will run separately from the main set of worker pods, at a different time. As long as it can provide a list of the datasets it generated, we can integrate it with PPS. This could be as simple as a CSV dump in a directory that we poll for files periodically.
Tasks#
Each of the steps described in Lifecycle of Prompt Processing Outputs above will be handled as an independent task within the service. The only connection between tasks is via the data persisted in the state database.
The general structure of each task is simple:
Query the state database to identify datasets ready for the task
Execute code to transfer/delete/etc datasets
Update the state database
Step #1 is where we would apply policies like “dataset type x should be expired 90 days after publication.”
The actual work of Step #2 may be fanned out across multiple workers, but there will be a single central service that is responsible for enqueueing work and collecting results from the workers.
After a task runs to completion, the database is updated with the new state. The underlying Butler methods can be made idempotent, so we only need to record completion of tasks and do not need to persist an “in progress” state in the database. In the event of a crash, the service can pick up where it left off without any special retry logic.
User Interface#
A small web app will be written for displaying service status and running administrative commands. The Data Curation team will be monitoring and managing the publication process. Most of the time, publication will be hands-off and fully automatic, but unusual situations may arise that need manual intervention. The web app will be developed in response to the needs of Data Curation as we gain experience with this process.
Butler repositories containing Prompt Data Products#
Prompt Data Products originate in the embargo Butler repository, hosted in
the embargo rack at USDF. However, they remain there only until their 80-hour
embargo period has expired, at which point they move to other repositories and
are deleted from embargo to reclaim storage space.
There are four Butler repositories that will contain unembargoed data:
/repo/main, the primary repository at USDF for Rubin-internal end users.prompt_prep, a repository at USDF for managing data prior to publication. This is intended for use by publication tooling and the data curation team – general users should not accessprompt_prep.promptrepository at Googleidfprod, the production deployment of the Rubin Science Platform.promptrepository at Googleidfint, the testing environment for the Rubin Science Platform.
Having a separate integration test repository at Google allows us to test configuration and infrastructure changes without impacting external users.
There may eventually be a prompt repo at USDF, mirroring the structure of the
Google ones. This would be used by external users with a User Batch
allocation, because they will not be permitted to access the /repo/main
repository used by Rubin staff.
Storage of artifact files#
All four of the USDF post-embargo repositories share a single copy of the artifact files.
The primary destination for files after unembargo is the
prompt_prep Butler repository, which stores its files in the /sdf/data Weka
filesystem.
/repo/main also uses the /sdf/data Weka, but it has its own repository root
directory and references the files copied into prompt_prep using hard links.
This allows it to share the files with no risk of a dangling reference if files
are deleted from either repository.
The two Google prompt repositories access the files from the prompt_prep
directory using the Weka S3 gateway. The Butler server signs URLs to grant
end users access to S3. This requires some care in managing the lifetime of
these files – they must always be loaded into prompt_prep before Google
prompt, and removed from Google prompt before being deleted from
prompt_prep. prompt_prep exists primarily to serve as a staging area for
serving these files to prompt end users via S3.
Datasets of type raw are handled slightly differently. They have a separate
storage location in /sdf/data, outside the root of any Butler repository.
They are ingested into the Butler in direct mode, which means they they are
considered external datasets with a lifetime managed outside of the Butler.
There is a separate S3 bucket for serving raw datasets to end users.
There is an additional complication with serving raw datasets to users at
Google. Multiple raw images are combined into zip files for storage at USDF,
with a single zip containing all detectors for an exposure. However,
services like datalinker and the Portal expect to be able to reference each
image via HTTP as a separate file. We will develop and deploy a microservice
to provide an HTTP endpoint for on-the-fly extraction of a single image from a
zip.
Butler databases#
Postgres databases for /repo/main and prompt_prep are hosted at USDF.
Each Google prompt repository has an
AlloyDB database hosted at Google,
close to the Butler server instances that serve data from them. A deployment of the
AlloyDB Auth Proxy
at USDF will allow publication tooling and the data curation team to access these
databases remotely from inside USDF.
Butler configurations prompt_google_prod and prompt_google_int will be
provided at USDF to allow the data curation team to manage these Butler
repositories the same way they manage USDF-internal repositories. This is not
expected to be a common occurence, but may be required for ad-hoc modifications
(e.g. to fix incorrect exposure metadata.)
Butler Collection Structure#
Although many datasets will be deleted from disk after 30 days, we need to retain a record of all the datasets that have ever been available in the Butler repository. This allows users to look up the dataset ID, provenance graphs, and other information needed to re-create the dataset. The following collection structure would allow users to distinguish datasets that are available for download from those that have been deleted:
Prompt/All CHAINED
Prompt/Available CHAINED
LSSTCam/raw/all RUN
Prompt/Outputs/Available TAGGED
Prompt/Calibs CHAINED
... replicate calibration chain structure from embargo ...
Prompt/Outputs/Expired TAGGED
Prompt Publication Service would manage the Prompt/Outputs/Available and
Prompt/Outputs/Expired tagged collections as part of the publication process.
Most tutorials and common use cases would point to Prompt/Available as the
default top-level collection.